PDFのOCR: スキャンPDFをテキスト化
⏱ 1分以内に完了
スキャンした紙の書類や画像ベースのPDFは、そのままでは検索もコピーもできません。PDFredoの無料OCRツールなら、文字を自動認識して検索・選択可能なPDFに変換します。日本語を含む複数言語に対応し、EU(ドイツ)のサーバーで安全に処理されます。
完全無料登録不要EUサーバー
OCR PDFを無料で試す →1
スキャンPDFをアップロード
「ファイルを選択」をクリックするか、PDFをアップロードエリアにドラッグ&ドロップしてください。最大100MBまで対応しています。
2
認識言語を選択
日本語・英語など、書類の主な言語を選びます。複数言語の混在にも対応しています。
3
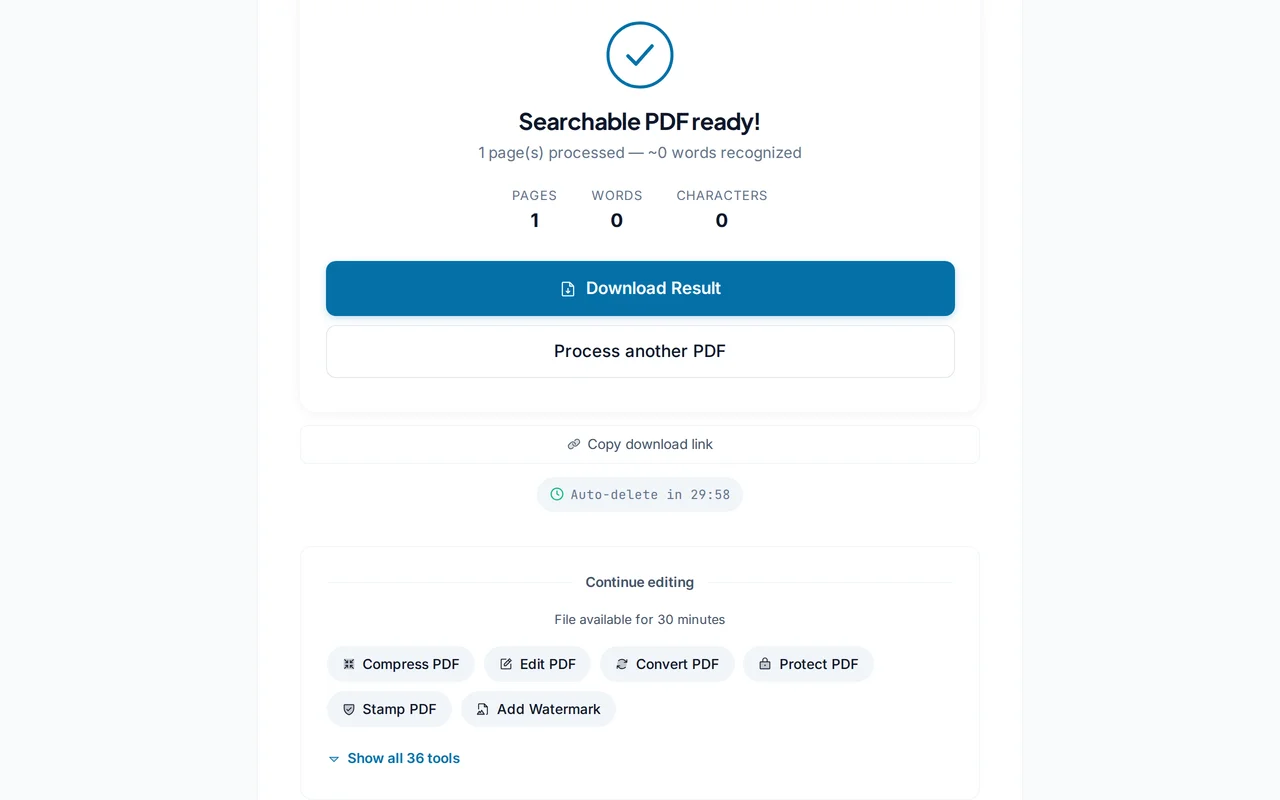
OCR済�みPDFをダウンロード
「OCRを実行」をクリックすると、文字認識が開始されます。処理時間はページ数に応じて変動します。完了後「ダウンロード」で保存してください。
プロのヒント
- 解像度が高いスキャン(300dpi以上)ほど認識精度が向上します。
- 傾いているスキャンは、先に「回転」ツールでまっすぐに直すと精度が上がります。
よくある質問
日本語の認識精度は?
▾
一般的な印刷物では高い精度で認識されます。手書き文字、極端に小さい文字、装飾的なフォントは認識精度が下がる場合があります。
認識できる言語は?
▾
日本語・英語・中国語・韓国語など主要言語に対応し、複数言語の混在も処理できます。
ファイルは安全に扱われますか?
▾
ファイルはEU(ドイツ)のサーバーで処理され、30分後に自動削除されます。共有や永続保存は行いません。
無料で使えますか?
▾
はい、完全無料です。登録もウォーターマークもありません。
元のレイアウトは保持されますか?
▾
はい。元のPDFに検索可能なテキスト層を重ねるため、見た目は変わらずにテキスト検索が可能になります。
OCR結果はWordにエクスポー��トできますか?
▾
はい。OCR後に「PDFからWord」ツールを使えば、編集可能なDOCXに変換できます。