PDF OCR: 스캔 문서 텍스트 인식 무료
⏱ 1분 이내 완료
스캔된 PDF에서 텍스트를 복사하거나 검색하고 싶으신가요? PDFredo의 무료 OCR 도구는 한국어를 포함한 여러 언어를 인식해 검색 가능한 PDF로 변환합니다. 가입이나 워터마크 없이 사용할 수 있으며, 파일은 EU(독일) 서버에서 처리된 뒤 30분 후 자동 삭제됩니다.
100% 무료회원가입 불필요EU 서버
OCR PDF 무료로 사용하기 →1
PDF 업로드
"파일 선택"을 클릭하거나 스캔한 PDF를 드래그 앤 드롭하세요. 최대 100MB까지 지원합니다.
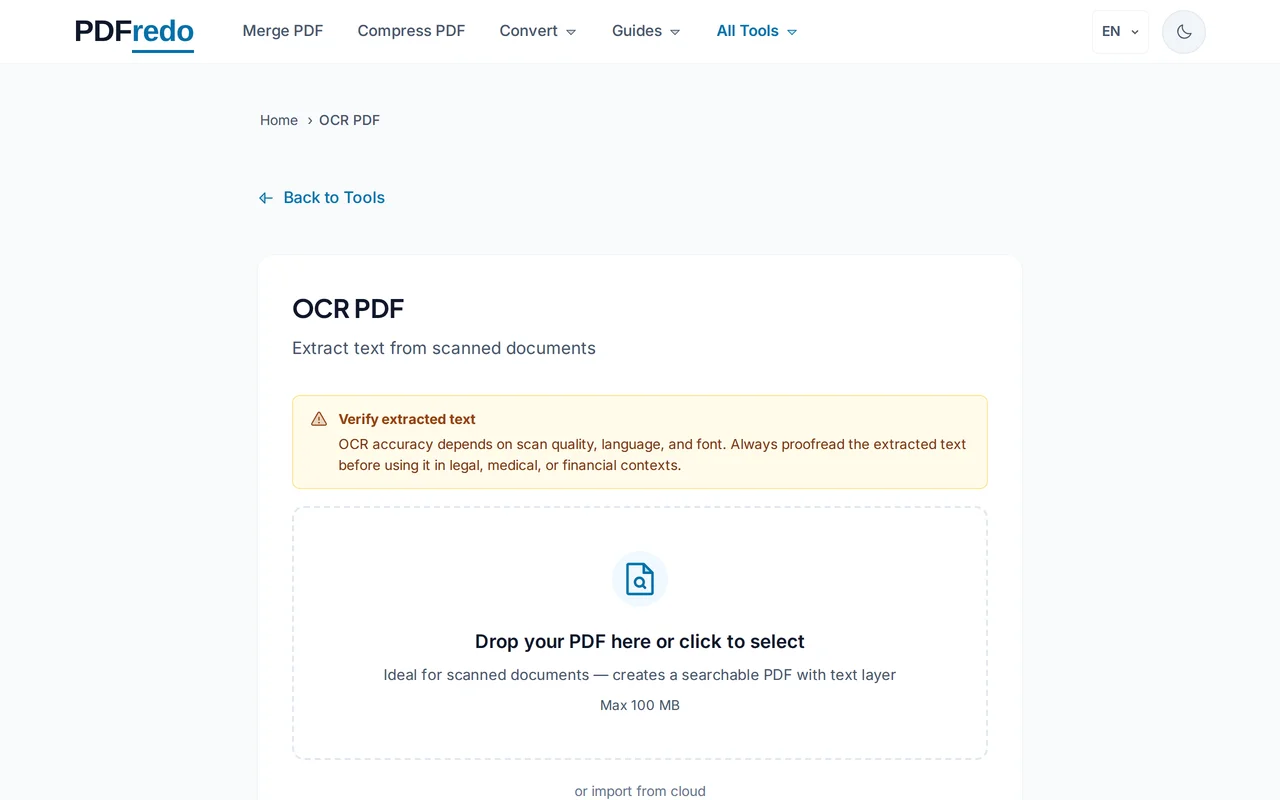
2
언어 선택
문서의 주요 언어를 선택하세요(한국어, 영어, 일본어, 중국어 등). 여러 언어가 섞여 있을 경우 복수 선택도 가능합니다.
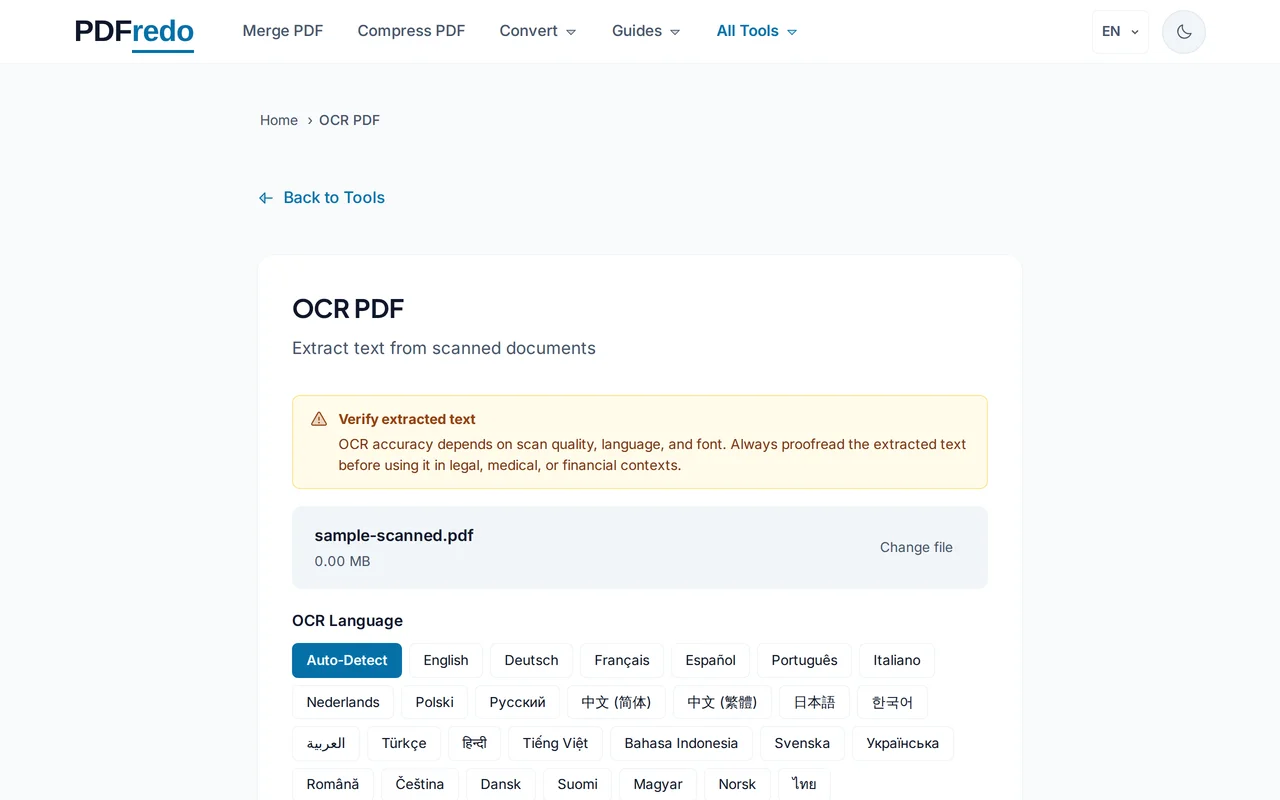
3
결과 다운로드
"OCR 실행"을 클릭하면 안전한 EU 서버에서 텍스트 레이어가 추가된 검색 가능한 PDF로 변환됩니다.
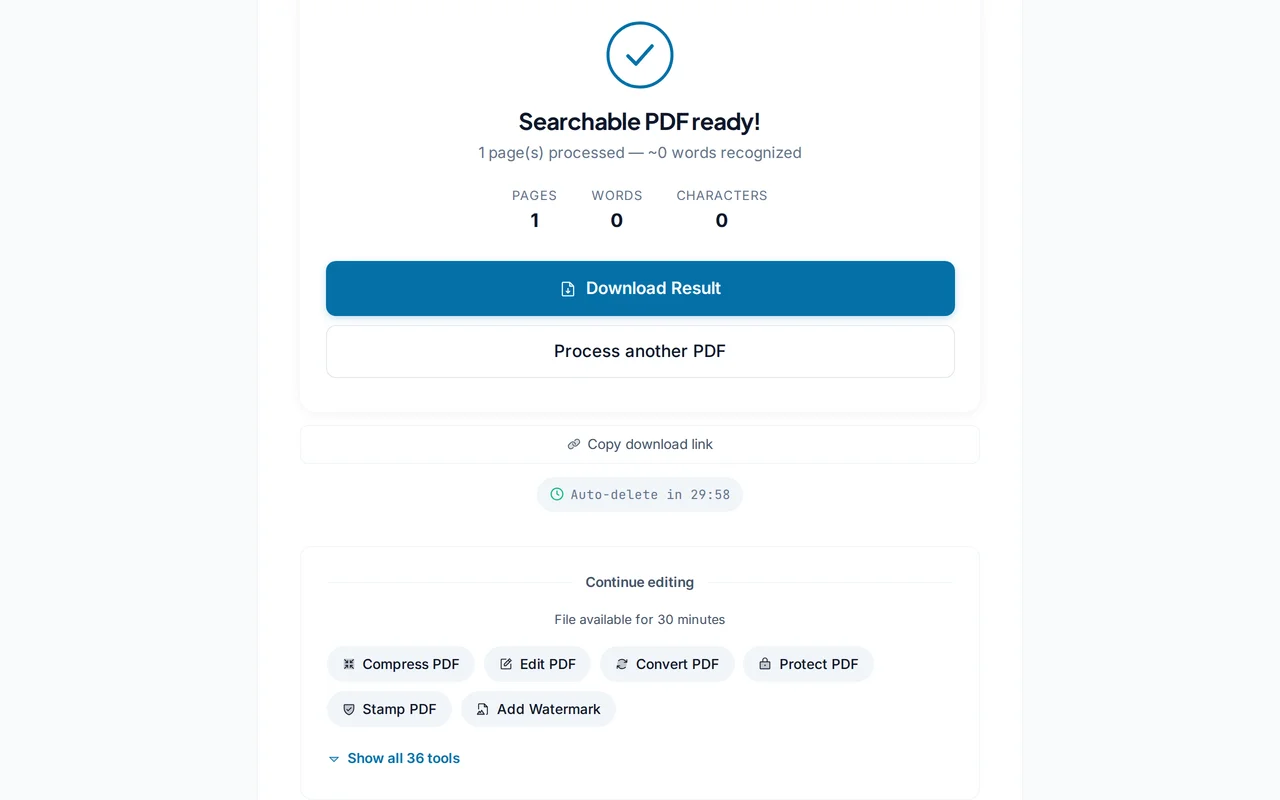
전문가 팁
- 스캔 해상도는 300 DPI 이상일 때 인식률이 가장 높습니다.
- 문서가 기울어져 있으면 회전 도구로 먼저 똑바로 맞추세요.
- OCR 후에는 복사, 검색, 요약 등 일반 텍스트 PDF처럼 활용할 수 있습니다.
자주 묻는 질문
한국어도 인식되나요?
▾
네. 한국어는 물론 영어, 일본어, 중국어, 독일어 등 100개 이상의 언어를 지원합니다.
인식 정확도는 얼마나 되나요?
▾
깨끗한 스캔 문서의 경우 95% 이상의 정확도를 기대할 수 있습니다. 손��글씨나 저해상도 스캔은 정확도가 떨어질 수 있습니다.
파일은 안전하게 처리되나요?
▾
파일은 EU(독일) 서버에서 처리되며 30분 후 자동 삭제됩니다. 인식된 텍스트도 외부로 전송되지 않습니다.
무료로 사용할 수 있나요?
▾
네, 가입과 워터마크 없이 완전 무료입니다.
OCR 후 편집할 수 있나요?
▾
네. OCR로 만들어진 텍스트 레이어는 "PDF 편집" 도구에서 수정할 수 있습니다.
모바일에서도 가능한가요?
▾
네. iOS와 Android 브라우저에서 바로 사용할 수 있습니다.