OCR PDF online: gör skannade PDF-filer sökbara
⏱ Tar mindre än 1 minut
Har du skannade PDF-filer där du inte kan söka eller kopiera text? PDFredos kostnadsfria OCR-verktyg känner igen text i bilder och gör dina dokument fullständigt sökbara. Utan konto, utan vattenstämplar och säkert på EU-servrar i Tyskland.
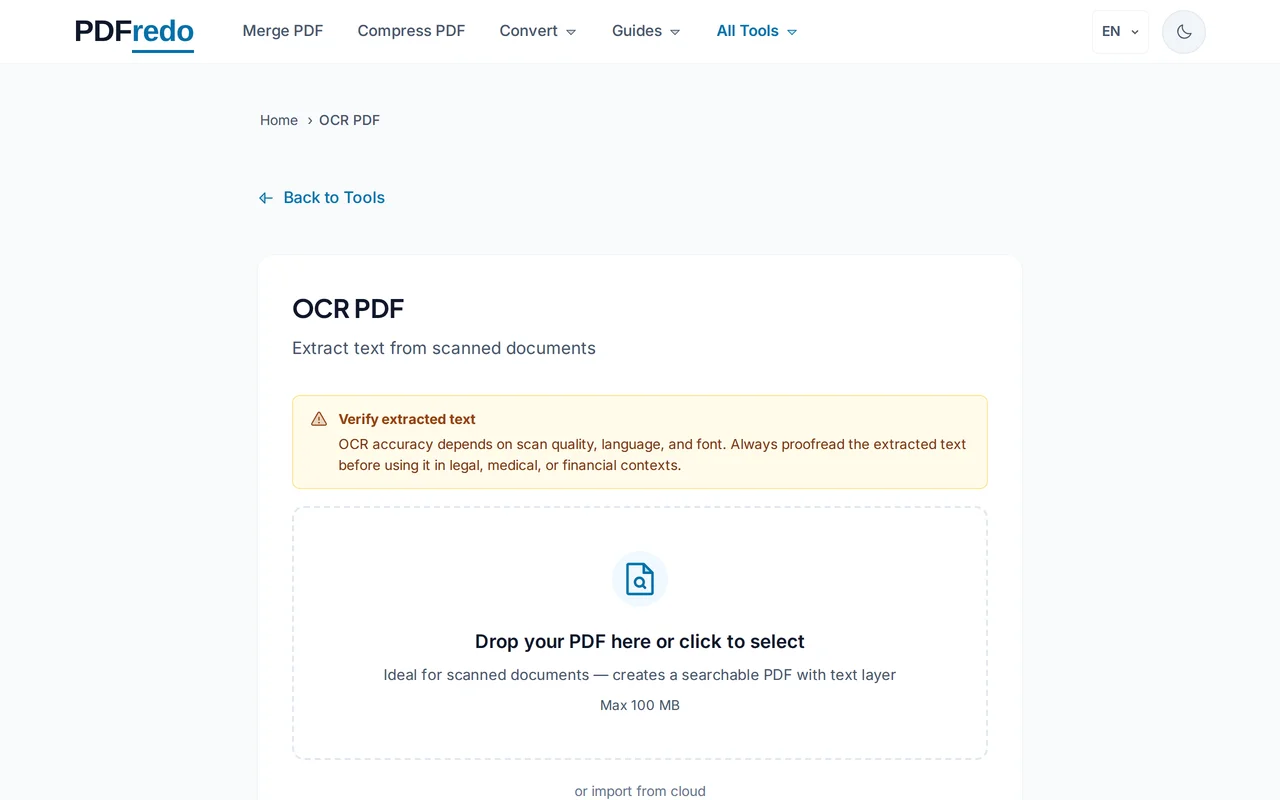
Ladda upp din skannade PDF
Klicka på "Välj fil" eller dra och släpp din PDF i uppladdningsområdet. Filer upp till 100 MB stöds.
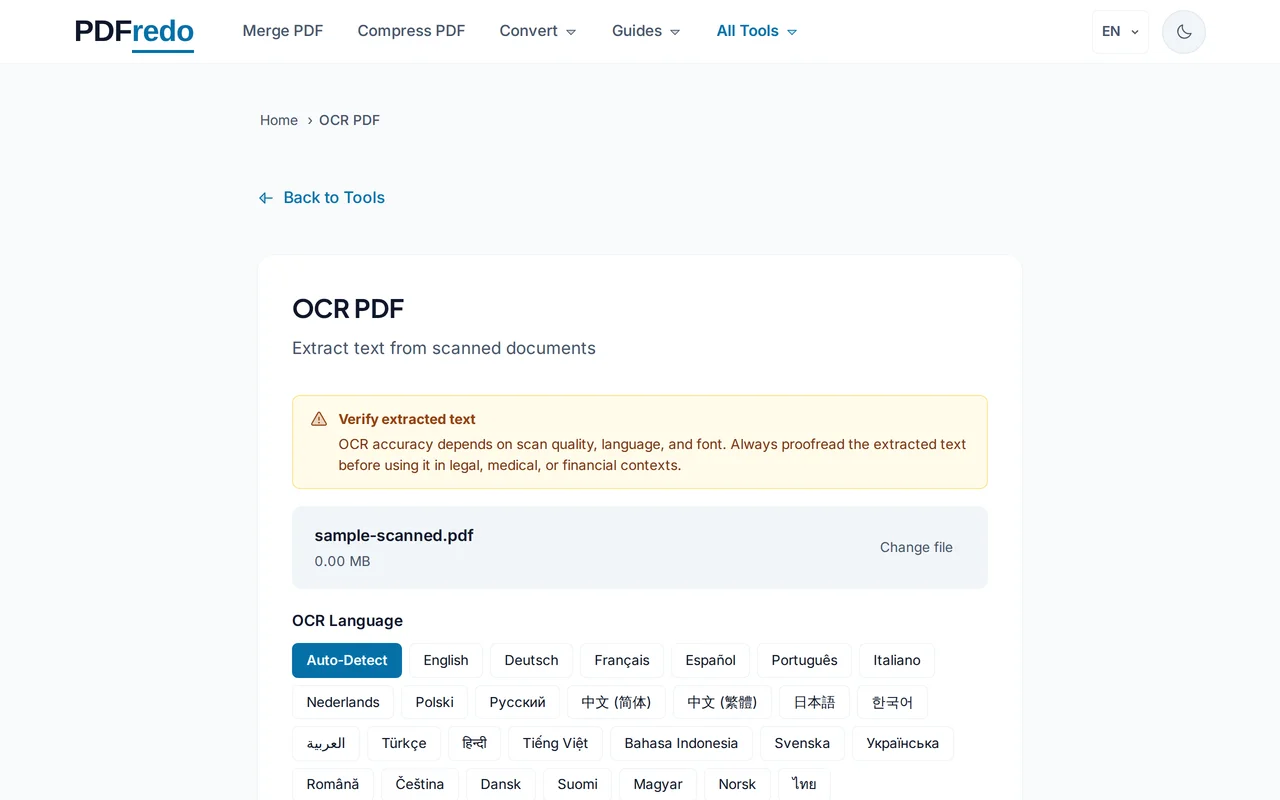
Välj språk
Välj språket som texten är skriven på (svenska, engelska, tyska m.fl.) för bästa igenkänningsresultat. Flerspråkiga dokument stöds också.
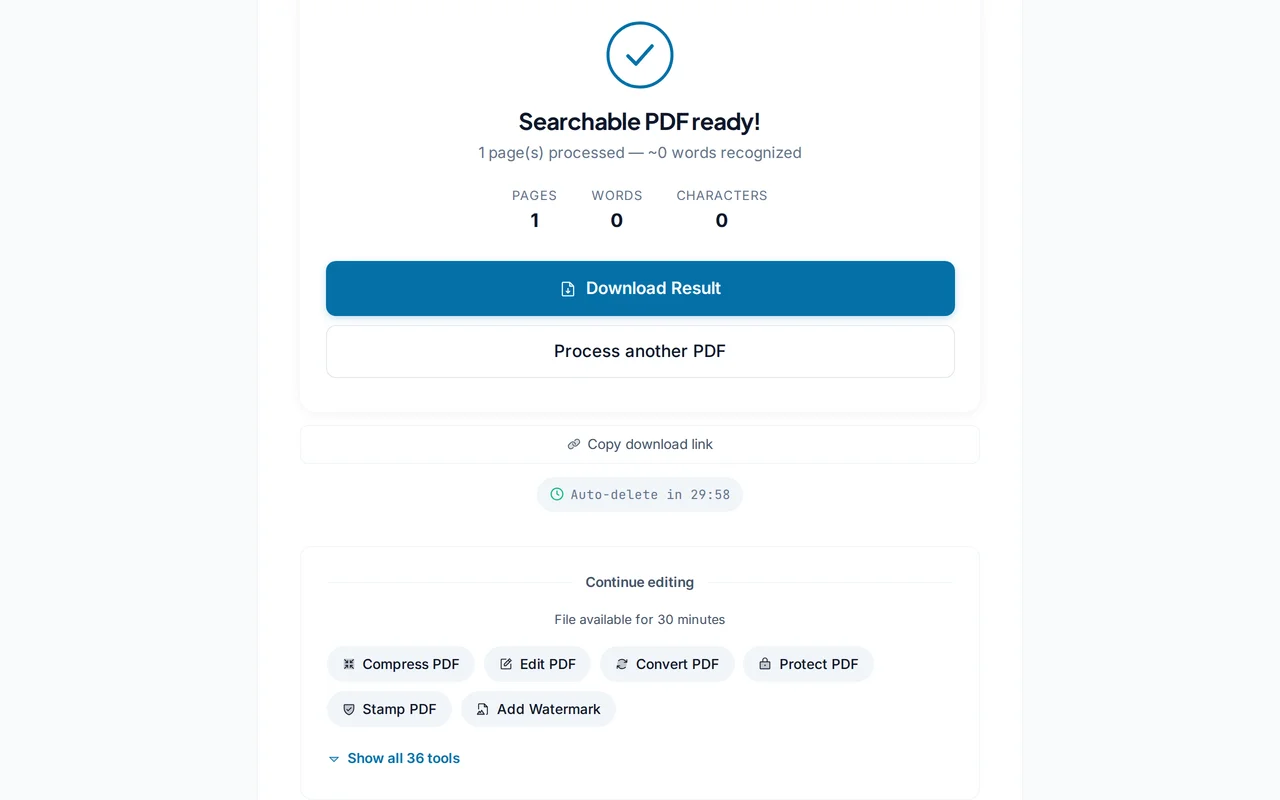
Ladda ner den sökbara PDF:en
Klicka på "Kör OCR". PDFredo analyserar sidorna och bäddar in ett textlager. Ladda sedan ner din sökbara PDF.
Proffstips
- Skanna i minst 300 DPI för bäst OCR-resultat. Lägre upplösning ger fler felläsningar.
- Rensa sneda skanningar och fläckar med ett bildredigeringsverktyg innan OCR. Det förbättrar träffsäkerheten.
Vanliga frågor
Vilka språk stöds?
▾
Över 100 språk, bland annat svenska, engelska, tyska, franska, spanska, italienska, nederländska, polska och ryska.
Är OCR 100 % exakt?
▾
Ingen OCR är felfri. Ren text i hög upplösning ger nästan perfekt resultat, handskriven text och dålig skanning ger fler fel.
Är mina filer säkra?
▾
Alla filer behandlas på EU-servrar (Tyskland) och tas automatiskt bort efter 30 minuter.
Kostar det något?
▾
Nej. Helt gratis, ingen registrering, inga vattenstämplar.
Behåller jag den ursprungliga layouten?
▾
Ja. OCR-lagret läggs över de ursprungliga bilderna. Visuellt ser PDF:en likadan ut, men texten blir nu sökbar och kopierbar.
Vilken är maximal filstorlek?
▾
Upp till 100 MB per fil.