PDF OCR: Taranmış Belgeleri Aranabilir Yap
⏱ 1 dakikadan az sürer
Taradığın belgedeki metni arayamıyor ya da kopyalayamıyor musun? PDFredo'nun ücretsiz OCR aracı Türkçe dahil onlarca dili tanıyarak görüntüleri gerçek metne dönüştürür. Üyelik yok, filigran yok; dosyaların AB sunucularında (Almanya) işlenir ve 30 dakika sonra otomatik silinir.
Taranmış PDF'yi yükle
"Dosya Seç" düğmesine tıkla veya taranmış PDF'yi yükleme alanına sürükle bırak.
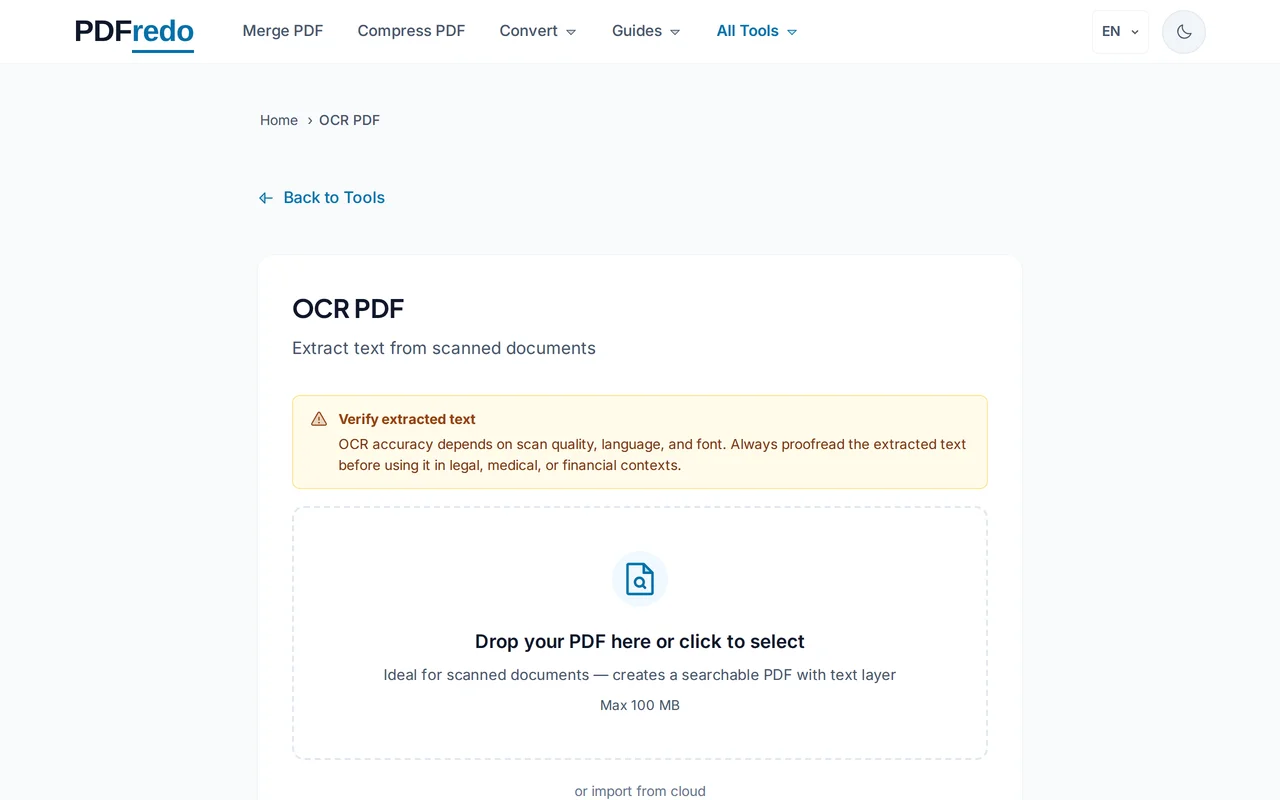
Dili seç
Belgedeki ana dili listeden seç (Türkçe, İngilizce, Almanca vb.). Birden fazla dil içeren belgeler için ek diller ekleyebilirsin.
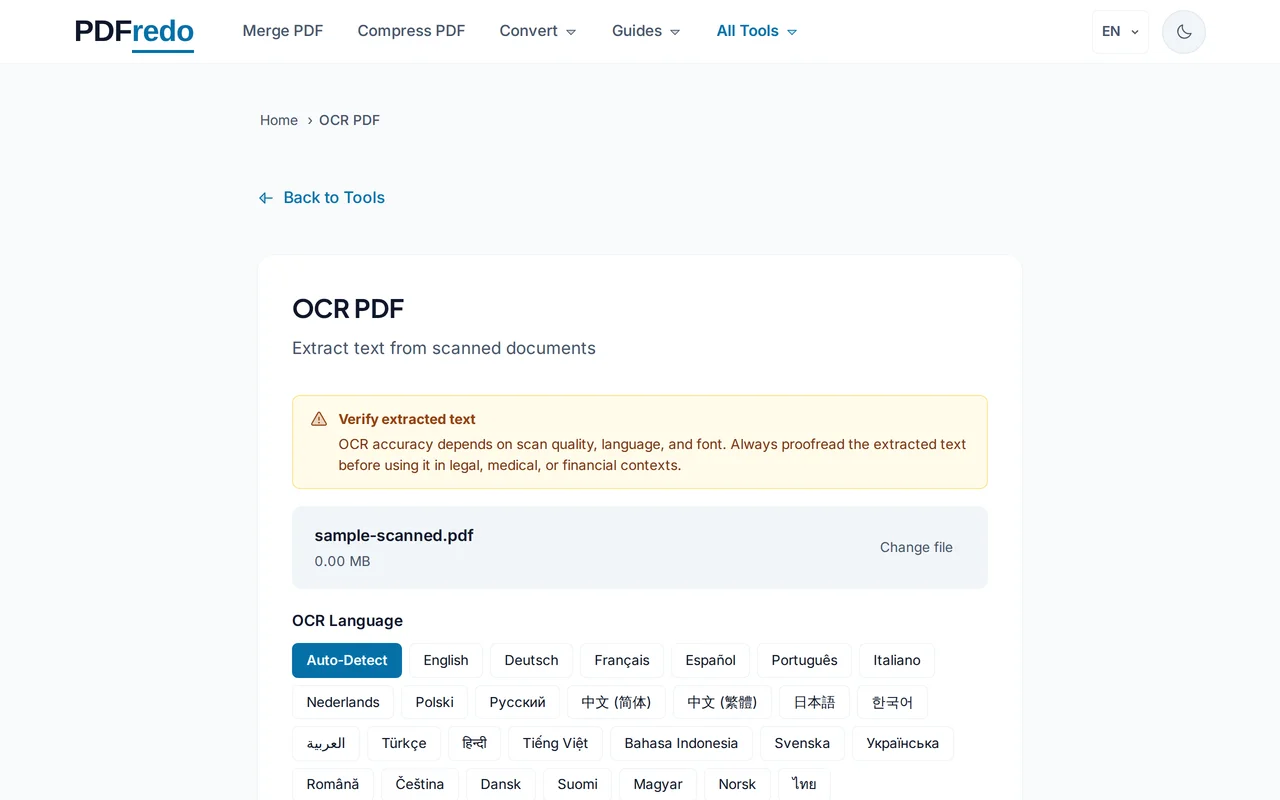
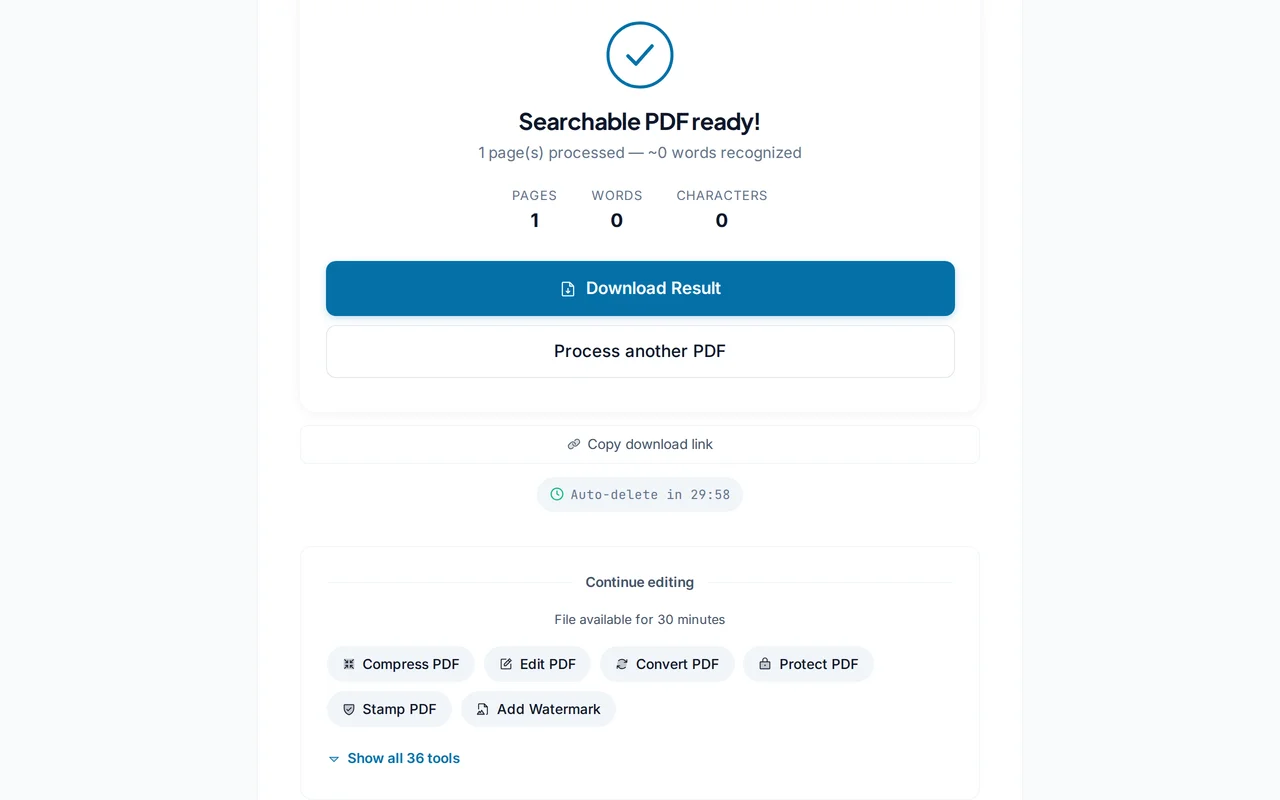
Aranabilir PDF'yi indir
"Metin Tanı" düğmesine tıkla. Bittiğinde "İndir" ile artık metni seçilebilir ve aranabilir yeni dosyayı al.
Uzman İpuçları
- En iyi sonuç için taramalar düz, iyi aydınlatılmış ve en az 300 DPI çözünürlükte olmalı.
- Çok dilli belgelerde birincil dili doğru seç; yanlış dil seçimi tanıma doğruluğunu düşürür.
- Metni Word ya da Excel'e aktarmak istersen, OCR sonrası "PDF'den Word'e" ya da "PDF'den Excel'e" aracını kullan.
Sık Sorulan Sorular
Hangi diller destekleniyor?
▾
Türkçe dahil 50'den fazla dil desteklenir; İngilizce, Almanca, Fransızca, İspanyolca, Arapça ve daha fazlası mevcuttur.
Tanıma doğruluğu ne kadar?
▾
Temiz, 300 DPI üzerindeki taramalarda doğruluk genellikle %95'in üzerindedir. Düşük çözünürlük veya bozuk el yazısı doğruluğu düşürür.
Dosyalarım güvende mi?
▾
Dosyalar AB sunucularında (Almanya) işlenir ve 30 dakika sonra otomatik silinir.
El yazısı tanınır mı?
▾
El yazısı tanıma sınırlıdır ve düzgün, blok harflerde çalışır. Yazı stiline göre sonuçlar değişir.
OCR ücretsiz mi?
▾
Evet, tamamen ücretsiz. Üyelik yok, filigran yok.
Orijinal görsel kalitesi korunur mu?
▾
Evet. OCR, orijinal tarama üzerine görünmez bir metin katmanı ekler; görsel görünüm değişmez.