PDF en texte gratuitement: extraire texte brut PDF
⏱ Prend moins d'1 minute
Vous voulez récupérer le texte d'un PDF sans mise en forme pour l'analyser, le traduire ou l'indexer ? L'outil gratuit PDF vers Texte de PDFredo extrait le contenu brut au format .txt, avec OCR intégré pour les documents scannés. Sans compte, sans filigrane, avec effacement des fichiers de nos serveurs UE après 30 minutes.
Téléversez votre PDF
Chargez le document. PDFredo détecte s'il s'agit de texte natif ou d'images nécessitant l'OCR.
Paramétrez l'extraction
Choisissez l'encodage (UTF-8 recommandé), activez l'OCR si nécessaire et sélectionnez la langue pour améliorer la précision.
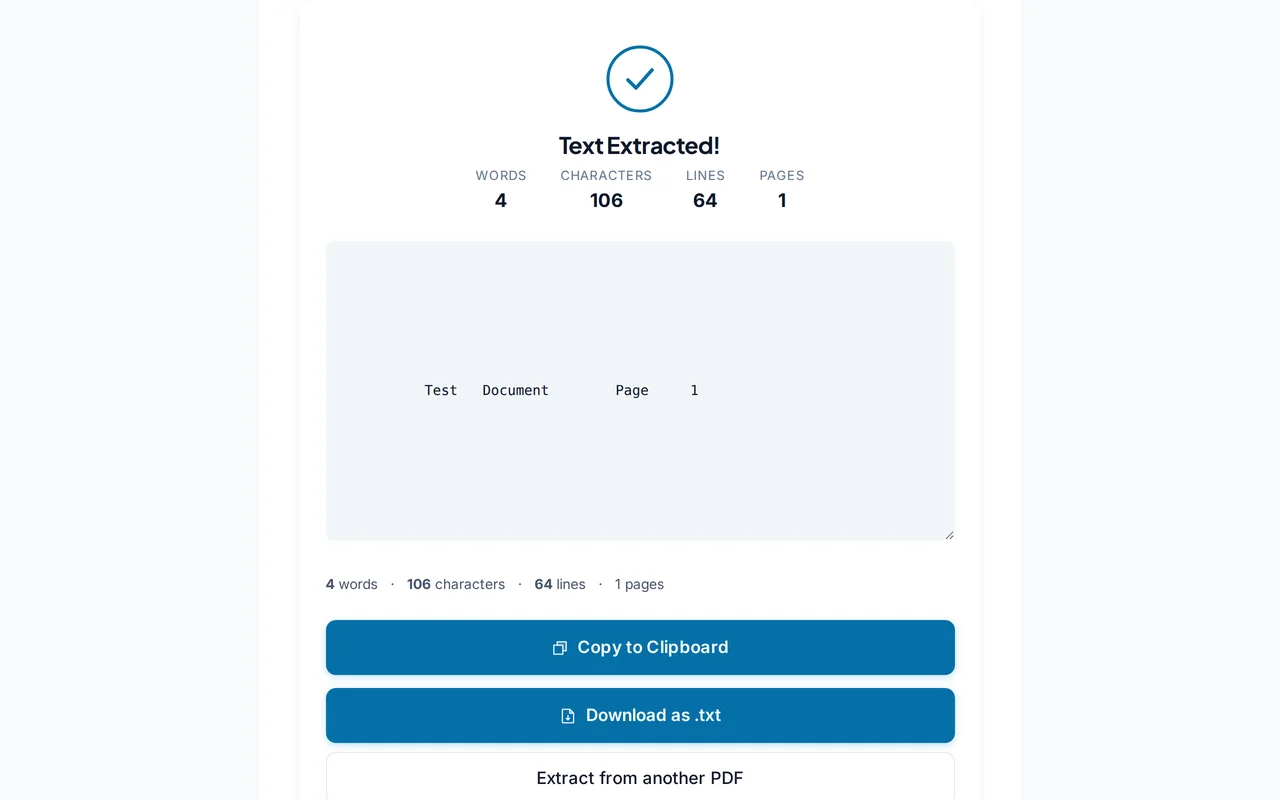
Téléchargez le fichier texte
Cliquez sur "Extraire le texte". Le .txt obtenu contient tout le contenu dans l'ordre de lecture.
Conseils pro
- UTF-8 gère tous les caractères accentués. Préférez-le à ANSI.
- Pour les PDF scannés, vérifiez la sortie OCR : la précision dépend de la qualité du scan.
- Pour garder la mise en page (tableaux, colonnes), préférez PDF vers Word.
Questions fréquentes
La mise en page est-elle préservée ?
▾
Non. L'extraction est en texte brut. Pour garder la mise en page, utilisez PDF vers Word.
Les PDF scannés sont-ils supportés ?
▾
Oui. L'OCR multilingue convertit les images en texte.
Le service est-il gratuit ?
▾
Oui. 100% gratuit, sans inscription, sans filigrane.
Mes fichiers sont-ils confidentiels ?
▾
Traitement sur serveurs UE (Allemagne) et suppression automatique après 30 minutes.
Quel encodage est utilisé ?
▾
UTF-8 par défaut (recommandé). ANSI et UTF-16 disponibles en option.
Puis-je extraire seulement certaines pages ?
▾
Oui. Indiquez une plage (ex. 1-5) avant extraction.
Quelle est la taille maximale ?
▾
Jusqu'à 100 Mo par PDF.