OCR PDF gratuit: reconnaissance de texte multilingue
⏱ Prend moins d'1 minute
Vos PDF scannés ne permettent ni recherche ni copier-coller ? L'outil OCR de PDFredo applique la reconnaissance optique de caractères pour rendre le texte sélectionnable et indexable, avec prise en charge multilingue (français, anglais, allemand, espagnol, et plus). Gratuit, sans compte, fichiers effacés de nos serveurs UE après 30 minutes.
Téléversez votre PDF scanné
Chargez le document. PDFredo détecte automatiquement s'il contient des images à traiter.
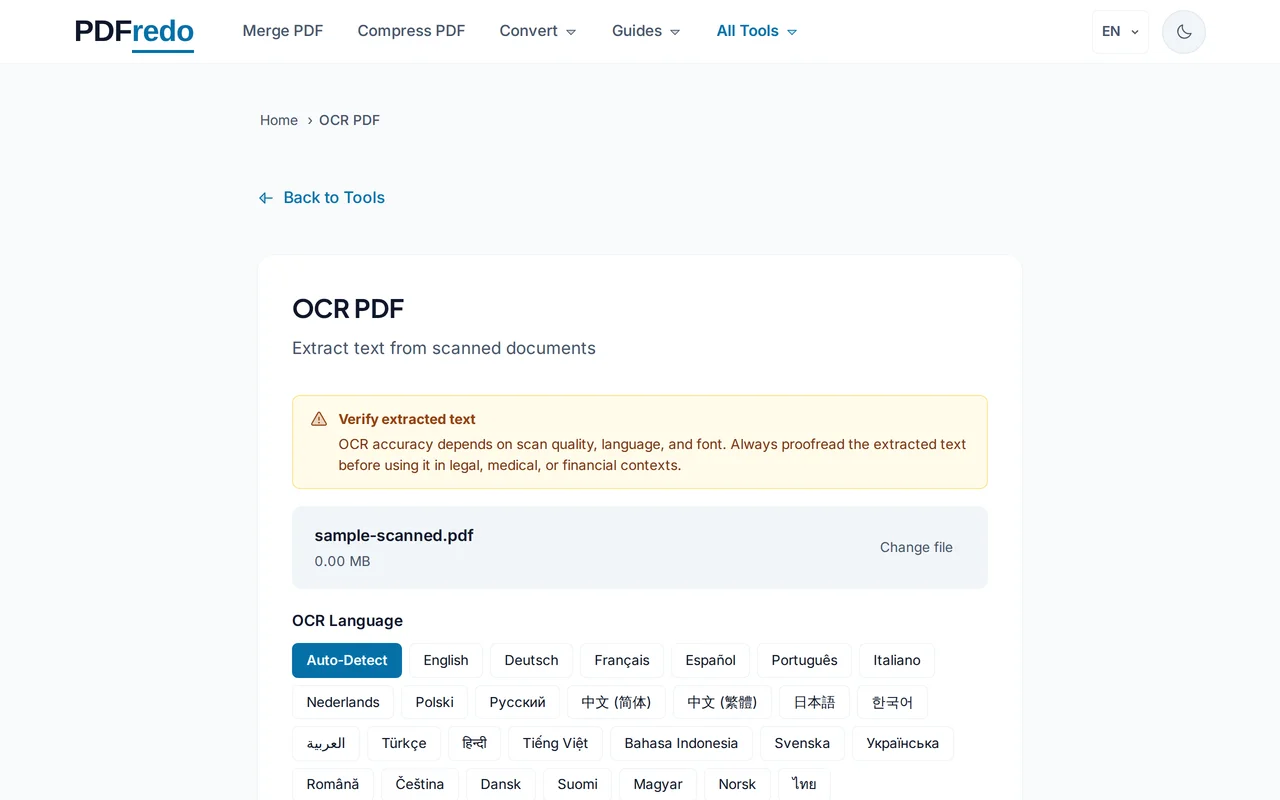
Choisissez la langue du document
Sélectionnez la langue principale (ou plusieurs) pour améliorer la précision de la reconnaissance.
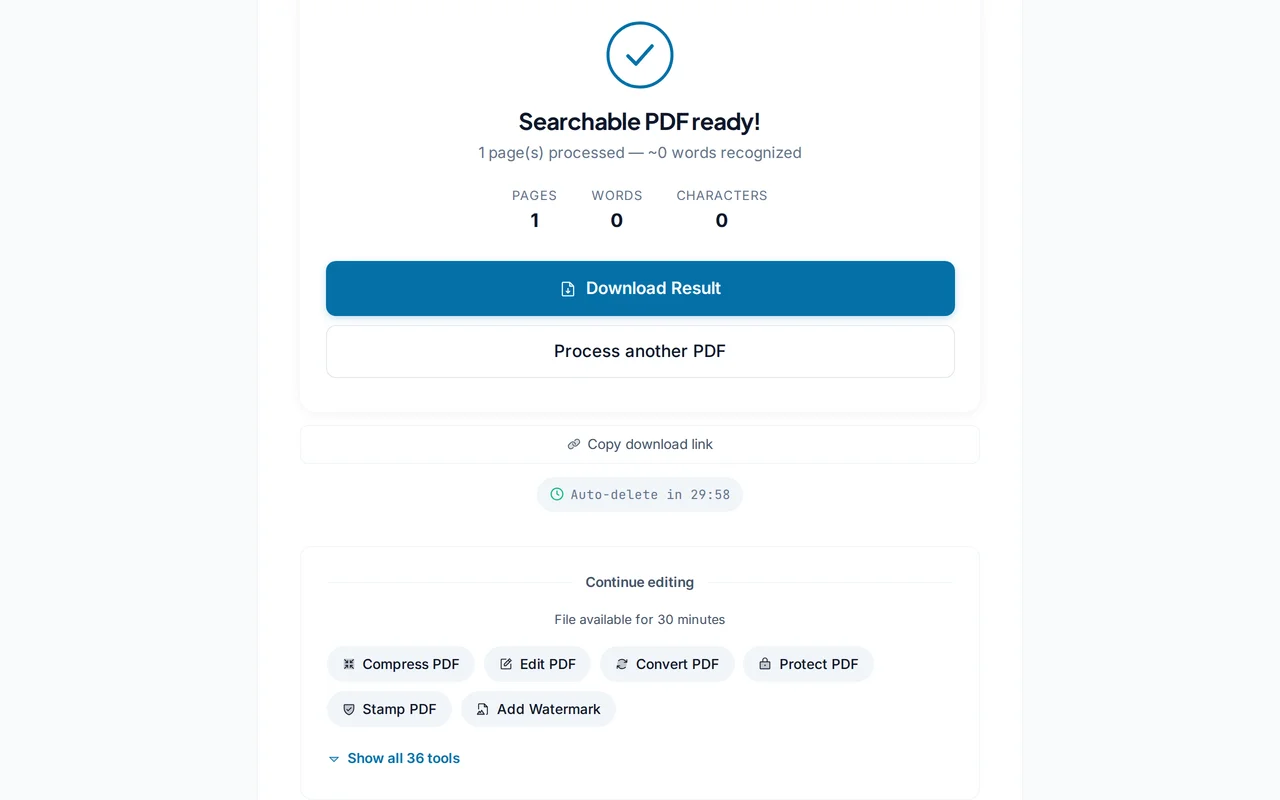
Téléchargez le PDF avec OCR
Cliquez sur "Lancer l'OCR". Le PDF obtenu contient une couche de texte sélectionnable par-dessus l'image.
Conseils pro
- Un scan à 300 dpi ou plus donne les meilleurs résultats. Les documents flous baissent la précision.
- Pour les documents bilingues, sélectionnez les deux langues pour améliorer la reconnaissance.
- Après OCR, utilisez PDF vers Word ou PDF vers Texte pour extraire le contenu dans un format éditable.
Questions fréquentes
Quelles langues sont supportées ?
▾
Français, anglais, allemand, espagnol, italien, portugais, néerlandais, plus d'autres. Sélectionnez-en plusieurs au besoin.
La précision est-elle garantie à 100% ?
▾
Non. L'OCR dépend de la qualité du scan. Comptez 95-99% sur un document net, moins sur du texte manuscrit ou flou.
Le service est-il gratuit ?
▾
Oui. 100% gratuit, sans inscription, sans filigrane.
Mes fichiers sont-ils confidentiels ?
▾
Traitement sur serveurs UE (Allemagne) et suppression automatique après 30 minutes. Aucun stockage durable.
Le fichier original est-il modifié ?
▾
Non. PDFredo génère un nouveau PDF avec couche de texte, sans toucher à l'image d'origine.
Puis-je faire de l'OCR sur du texte manuscrit ?
▾
La précision est limitée sur le manuscrit. L'OCR est optimisé pour le texte imprimé.
Quelle est la taille maximale ?
▾
Jusqu'à 100 Mo par PDF.