PDF OCR: Scanned PDF को searchable बनाएँ मुफ्त
⏱ 1 मिनट से कम समय लगता है
Scanned PDFs में text select नहीं हो पाता? PDFredo का मुफ्त OCR tool scanned documents या images से text पहचानता है और searchable, copyable PDF बनाता है। कई भाषाएँ समर्थित। EU सर्वर (जर्मनी) पर process, files 30 मिनट बाद डिलीट।
अपनी PDF अपलोड करें
"Select File" पर क्लिक करें या PDF को drag करें। 100 MB तक की files समर्थित हैं।
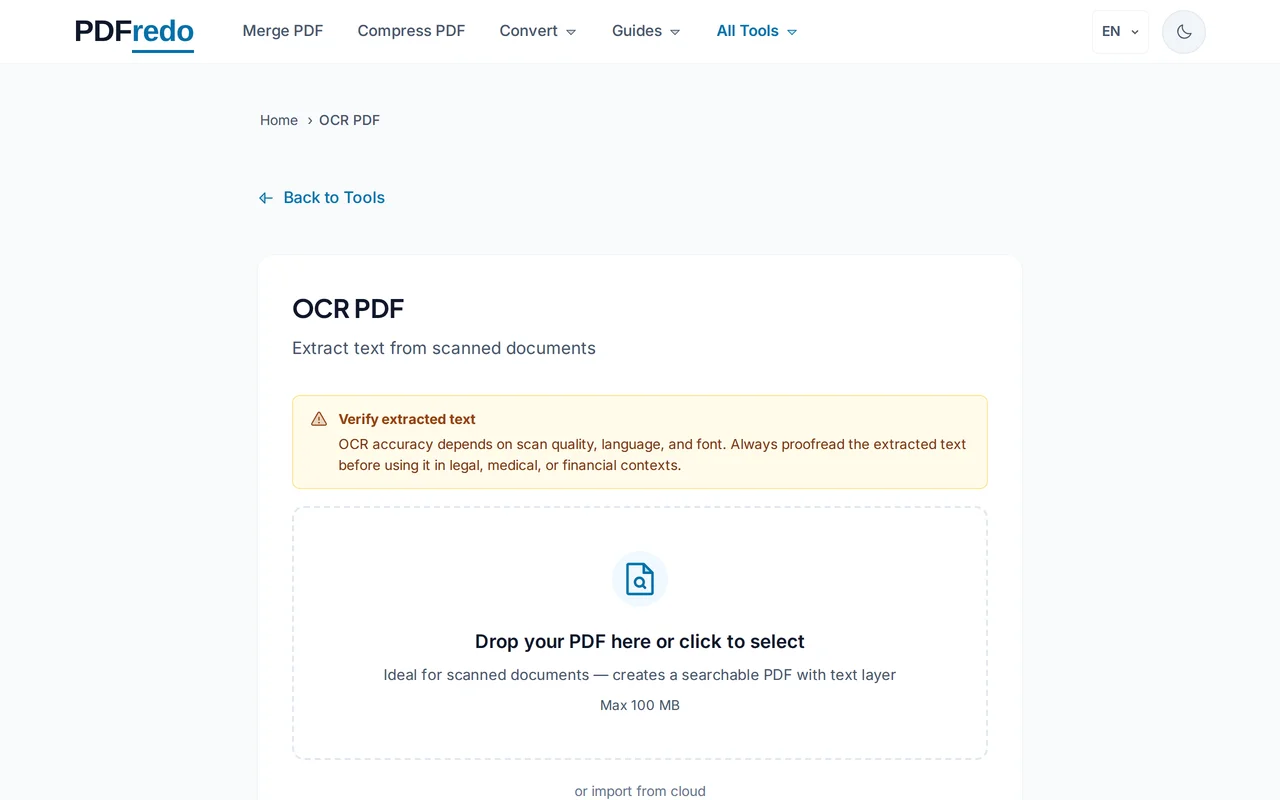
भाषा और mode चुनें
अपने document की मुख्य भाषा चुनें (Hindi, English, या अन्य)। Multi-language documents के लिए कई भाषाएँ चुनें।
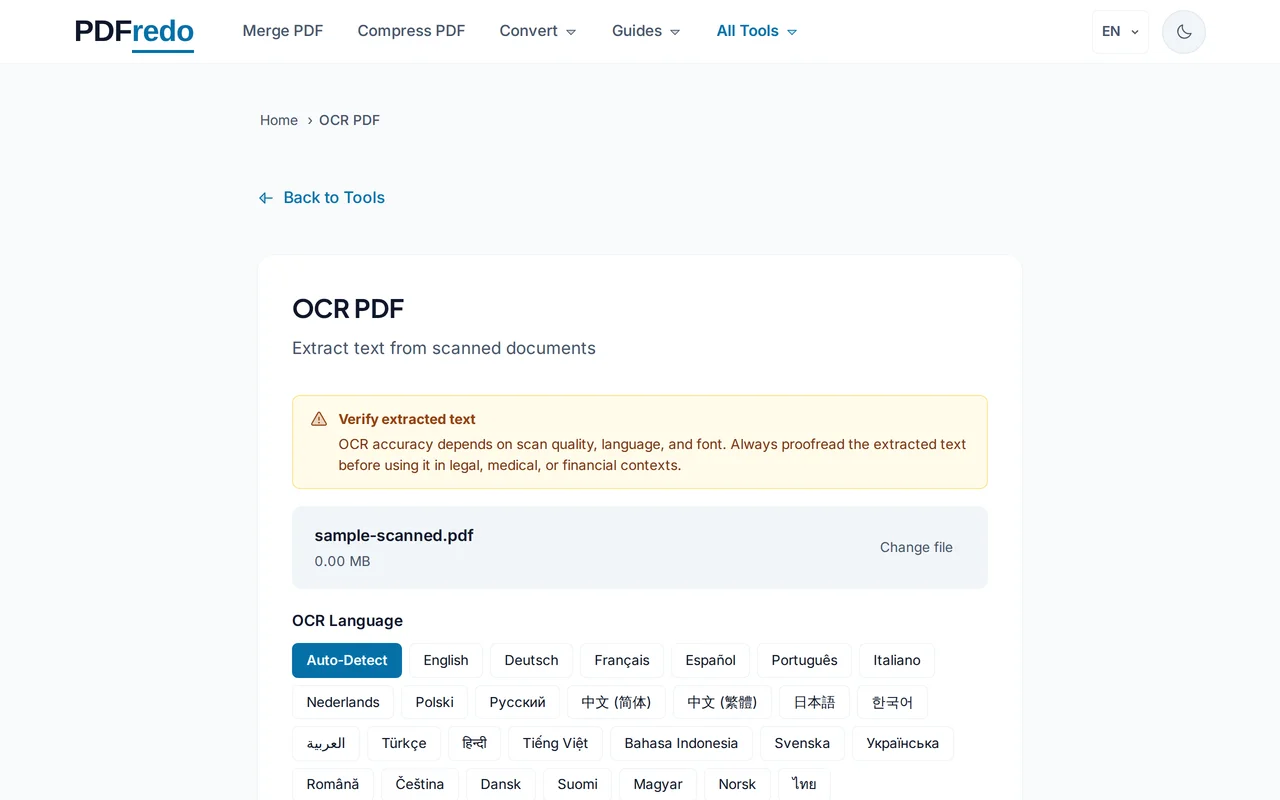
Searchable PDF डाउनलोड करें
"Run OCR" पर क्लिक करें। PDFredo text recognize करता है और एक searchable PDF लौटाता है। "Download" पर क्लिक करें।
प्रो टिप्स
- OCR गुणवत्ता scan resolution पर निर्भर करती है. सबसे अच्छे परिणाम के लिए 300 DPI आदर्श है।
- Handwritten text मज़बूती से support नहीं है; यह tool printed text के लिए optimized है।
- यदि आपको सिर्फ plain text चाहिए, पहले OCR चलाएँ फिर PDF-to-Text tool उपयोग करें।
अक्सर पूछे जाने वाले प्रश्न
कौन सी भाषाएँ समर्थित हैं?
▾
100+ भाषाएँ जिनमें Hindi, English, जर्मन, स्पेनिश, फ्रेंच, चीनी, जापानी, अरबी और कई और शामिल हैं।
क्या OCR handwriting पढ़ सकता है?
▾
यह tool printed text के लिए optimized है। Handwriting परिणाम अविश्वसनीय होते हैं।
क्या मेरी files सुरक्षित हैं?
▾
आपकी files EU सर्वर (जर्मनी) पर process होती हैं और 30 मिनट बाद स्वचालित रूप से डिलीट हो जाती हैं।
क्या यह tool मुफ्त है?
▾
हाँ. पूरी तरह मुफ्त, कोई रजिस्ट्रेशन नहीं, कोई वॉटरमार्क नहीं।
अधिकतम file size क्या है?
▾
प्रति file 100 MB तक।
क्या original layout बरकरार रहता है?
▾
हाँ. OCR original पेज images के ऊपर invisible text layer जोड़ता है, इसलिए आपका document दिखने में वैसा ही रहता है।